Why CI/CD Pipelines Matter More Than Ever in 2025
In 2025, continuous integration and continuous delivery aren’t just best practices — they’re baseline requirements. From startups to enterprise-level engineering teams, the ability to ship software quickly, safely, and repeatedly defines whether a business stays competitive or falls behind. With increasingly complex architectures — spanning containerized microservices, edge deployments, and infrastructure-as-code — the need for fully automated CI/CD pipelines has become central to modern DevOps.
But automation alone isn’t enough. Teams that succeed are those who treat their CI/CD pipeline not as a set of glued-together scripts, but as a disciplined system: observable, testable, secure, and adaptable. A well-designed pipeline helps engineers ship changes multiple times per day with confidence — while detecting failures early, rolling back cleanly, and reducing cognitive load across the team.
According to the 2024 State of DevOps Report by Puppet, elite teams deploy 973 times more frequently and resolve incidents 6,570 times faster than their peers. Their advantage? A streamlined, automated delivery lifecycle that integrates tightly with testing, security, and monitoring from the first commit to production.
This guide is built to take you from foundational concepts to advanced techniques. Whether you’re just exploring automation or looking to scale an existing system, you’ll learn how to design, implement, and improve a CI/CD pipeline using modern tools and proven approaches. We’ll cover topics like choosing the right automation platform, testing workflows, deployment strategies, secrets management, rollback processes, and observability — all backed by real examples from recent industry use.
CI/CD is not a one-size-fits-all practice. But when approached systematically, it becomes one of the most powerful levers in your software delivery lifecycle. Let’s dive in.
Core Steps to Build a CI/CD Pipeline in 2025
- Choose the right CI/CD platform
Tools like GitHub Actions, GitLab CI/CD, CircleCI, and Bitbucket Pipelines are widely used depending on your stack and team size. - Define pipeline triggers
Set up triggers for events like pull requests, merges, or tags to start the automation reliably. - Automate testing at every stage
Include unit, integration, and end-to-end tests as part of the pipeline to catch issues early. - Build and package your application
Use Docker, npm, or your stack’s specific tooling to package your app for consistent deployments. - Deploy using a repeatable strategy
Implement blue/green, rolling, or canary deployments to safely release changes without downtime. - Secure the pipeline
Store secrets with tools like HashiCorp Vault or GitHub OIDC, and validate config changes through pull requests. - Monitor deployments and set up rollbacks
Connect the CI/CD pipeline to logging and monitoring tools (like Prometheus or Datadog) to detect failures and enable fast rollbacks.
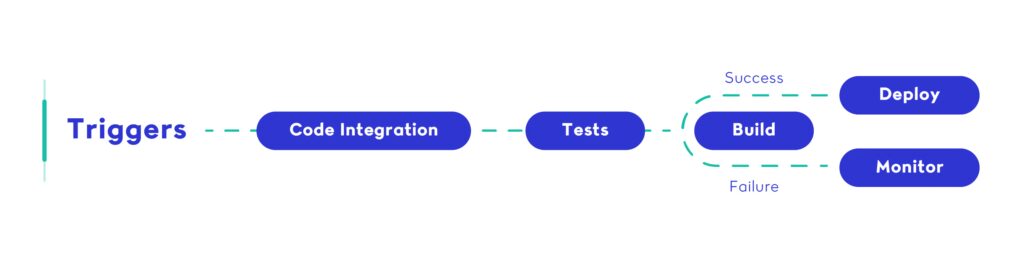
What is CI/CD? A Modern Definition (2025)
CI/CD stands for Continuous Integration and Continuous Delivery (or Deployment). In modern software development, it refers to the automated workflows that handle everything from code integration and testing to packaging and deployment. A robust CI/CD pipeline ensures that these processes are repeatable, fast, and free of human error.
At its core, a CI/CD pipeline is a series of interconnected steps triggered by a code change. These steps include running tests, building artifacts, validating environments, and deploying across staging and production. When implemented correctly, a CI/CD pipeline can significantly reduce release risk and improve developer velocity.
By 2025, the role of the CI/CD pipeline has expanded beyond simple code deployment. It’s now an essential backbone of platform engineering, observability, compliance, and even cost control. Modern teams integrate infrastructure-as-code, container orchestration, and policy enforcement directly into their CI/CD pipeline architecture.
For instance, Shopify engineers moved their massive codebase onto containerized pipelines using Google Cloud Build in 2023, allowing them to standardize their CI/CD pipeline across hundreds of services. That shift improved isolation, speed, and maintainability.
Regardless of whether you deploy weekly or hourly, building a secure, observable, and flexible CI/CD pipeline is one of the most impactful engineering investments in modern DevOps.
A Brief History: From Manual Releases to Continuous Flow
Before CI/CD pipelines became mainstream, deploying software was a risky, manual event. Teams would spend weeks preparing a release, freeze all development, and cross their fingers as code was moved to production. These waterfall-style processes caused long feedback loops, high failure rates, and slow iteration.
The earliest form of continuous integration emerged in the early 2000s as teams started running automated builds and tests on code pushes. But true velocity didn’t arrive until CI/CD pipelines connected integration with automated delivery. That shift allowed organizations to release smaller changes more frequently — with rollback and monitoring baked into the process.
By 2020, companies like Google, Netflix, and Amazon had already built internal platforms centered around scalable, self-healing CI/CD pipelines. Today, even small startups can implement similar systems using GitHub Actions, GitLab CI/CD, or Argo CD with relatively little overhead.
The evolution from manual release to fully automated CI/CD pipeline workflows has transformed software delivery into a continuous, data-driven, and resilient process. It set the foundation for modern DevOps, platform engineering, and GitOps as we know them today.
How CI/CD Works Today
A modern CI/CD pipeline is made up of automated steps that run every time code changes. These steps typically include:
- Triggering the pipeline
Pipelines are automatically triggered by version control events — like a pull request, commit to a branch, or tagging a release. - Running code quality and security checks
Linting, formatting, static analysis, and security scans are performed to catch issues early. - Executing automated tests
Unit, integration, and end-to-end tests validate functionality before anything is deployed. - Building and packaging the application
Code is compiled or bundled (e.g., with Docker, Webpack, or Maven) into deployable artifacts. - Deploying to environments
Artifacts are deployed to staging, QA, or production using controlled strategies like blue/green or canary deployments. - Monitoring and feedback
Tools like Prometheus, Grafana, and Sentry track the health of the application post-deploy, and failed steps trigger automated rollbacks or alerts.
All of this happens without human intervention — reducing manual steps, improving reliability, and shortening feedback loops across teams.
What CI/CD Means in 2025
The meaning of CI/CD has continued to evolve. It’s no longer just about testing and pushing code — it’s about managing risk, scaling infrastructure, and enabling continuous improvement.
Modern pipelines now include:
- Infrastructure-as-code integration
Tools like Terraform and Pulumi are embedded into pipelines to provision environments as part of the release process. - Security as code
Security scans (e.g., Snyk, Trivy) are automated and treated like any other quality gate — blocking deploys when vulnerabilities are found. - Policy enforcement and compliance
Pipelines include automated governance to enforce change approval, access control, and audit trails. - Distributed and parallel execution
Pipelines run across cloud-based runners, containers, or edge clusters, often executing dozens of steps in parallel.
This shift is visible in how leading companies approach delivery. For instance, in 2023, Spotify open-sourced their Backstage platform, which they use to help hundreds of teams manage self-service CI/CD pipelines in a standardized, scalable way. Similarly, Shopify’s engineering team detailed how they rebuilt their CI system on Google Cloud Build to support faster, isolated builds across their growing microservice ecosystem.
These examples reflect a common truth: mature engineering organizations treat CI/CD not as a script, but as infrastructure. It’s monitored, versioned, secured, and constantly improved.
An efficient CI/CD pipeline enables faster feedback, lower failure rates, shorter time-to-recovery, and safer releases. But more importantly, it aligns engineering velocity with business agility. Teams can ship new features, fix bugs, and respond to market shifts without waiting on manual handoffs or staging bottlenecks.
For organizations adopting platform engineering or moving toward internal developer platforms (IDPs), CI/CD is the primary automation layer that ties tools, environments, and teams together.
In short, CI/CD is not just a technical solution — it’s a strategic enabler.
Choosing the Right CI/CD Tool
Selecting the right tooling is a critical decision when building a maintainable and scalable CI/CD pipeline. It influences everything from onboarding and test orchestration to deployment velocity and long-term reliability. A tool that fits your team’s workflow will make your CI/CD pipeline easier to scale, easier to debug, and easier to improve over time.
In 2025, the tooling landscape is mature but also fragmented. There are platform-native options, self-managed setups, cloud-native orchestrators, and GitOps-ready solutions. Choosing the right one depends on where your code lives, how complex your workflows are, and what level of control you need over your pipeline environments.
The most effective CI/CD pipeline tools will support flexible triggers, secrets management, parallelism, and clear feedback visibility. More importantly, they must integrate smoothly into your broader engineering stack — whether that includes Kubernetes, serverless functions, container registries, or traditional monolith builds.

How to Evaluate CI/CD Tools
There are five key dimensions to evaluate when choosing a tool for your CI/CD pipeline:
- Code hosting integration
Many teams choose a tool based on where their code lives. For example, GitHub Actions integrates tightly with GitHub repos, while GitLab CI/CD offers end-to-end workflow automation for self-hosted or SaaS GitLab instances. - Pipeline complexity
Are you running a monolith with simple build steps, or managing 40+ microservices with matrix builds and deployment gates? Choose tools that scale with complexity without introducing maintenance overhead. - Developer ergonomics
The best tool is the one your team will actually use. YAML-heavy tools can be powerful but also brittle if not abstracted well. Look for clear syntax, local testing support, and reusable pipeline components. - Runtime control
Do you need hosted runners or control over your own infrastructure? CircleCI, GitLab, and Jenkins give flexibility to choose between cloud and self-managed agents. - Cost and scaling
A cheap tool for small workloads might become prohibitively expensive at scale. Look at caching support, build parallelism, and pay-per-minute pricing to understand your long-term cost curve.
Popular CI/CD Tools in 2025
Below are real-world tools used in production by companies in the last two years — each powering large-scale CI/CD pipelines.
GitHub Actions
Ideal for teams already using GitHub. GitHub Actions provides full integration into repo events, pull request gates, reusable workflows, and deployment environments. It’s often the fastest way to get a working CI/CD pipeline off the ground.
- See the GitHub Actions overview here.
- Example: Astro team migrated its entire CI flow to GitHub Actions in 2023, automating, testing, builds, and npm publishing.
GitLab CI/CD
Powerful for enterprise teams managing their own runners or needing tighter control across services. GitLab’s built-in observability and GitOps integrations make it suitable for multi-team CI/CD pipeline strategies.
- Check GitLab CI/CD overview here.
- Example: CERN uses GitLab CI/CD to run simulations on Kubernetes clusters across its research environments. Read more about it here.
CircleCI
Great for teams focused on speed and flexibility, particularly those working with Docker-based builds. CircleCI’s pipeline visualization tools and test insights help teams refine their CI/CD pipeline iteratively over time.
- Discover how to configure CircleCI in just a few steps — check out the full guide here.
- Example: i2 Group slashed one of its automated test suites from 18–24 hours down to just 1 hour by leveraging CircleCI’s caching, parallelism, orbs, and the Insights dashboard — delivering that suite in a fraction of the time than before.
Jenkins
Still widely used in hybrid and legacy environments. With plugins like Blue Ocean or integrations with Kubernetes, Jenkins can support advanced CI/CD pipelines — but often at the cost of higher maintenance overhead.
- See all about Blue Ocean UI project here.
- Example: The BBC rearchitected their Jenkins pipelines in 2023 to improve observability and support parallel deployment flows.
Argo CD
Argo CD is a declarative, GitOps-based delivery tool designed for Kubernetes. While it doesn’t replace your CI/CD pipeline entirely, it takes over the deployment layer, syncing infrastructure and app state from Git into clusters. It’s especially valuable for teams managing multiple environments or internal developer platforms.
- See Argo CD docs here.
- Example: Adobe scaled its internal GitOps platform with Argo CD to manage a fleet of over 50,000 applications across Kubernetes clusters, handling multi-tenancy, automated synchronization, and rollback at massive scales.
How to Choose the Best Fit
- Small to mid-sized teams
Start with GitHub Actions or GitLab CI/CD. They reduce friction, offer modern features, and integrate well with popular version control systems. - Enterprise DevOps teams
GitLab CI/CD and CircleCI provide richer governance, permissions, and audit logging. These are especially useful when multiple teams or business units manage their own pipelines. - Cloud-native platform teams
For those building IDPs (Internal Developer Platforms), tools like Argo Workflows or Tekton provide the flexibility and control needed for declarative, Kubernetes-first infrastructure. - Teams with legacy workloads
Jenkins (with modern plugins) still supports many legacy Java and monolith-based builds. However, maintenance effort is higher.
Ultimately, the best CI/CD pipeline is one you can extend, observe, and trust. Choose a tool that will evolve with your architecture — not constrain it.
Building a Minimal Viable Pipeline
A minimal viable CI/CD pipeline is the fastest way to start getting consistent, automated feedback on code changes without overwhelming your team. It’s the foundation that every mature delivery system builds on — allowing engineers to test, package, and deploy code confidently and repeatedly.
The goal of a minimal pipeline is not to do everything. It’s to do the right things: trigger builds on code changes, run meaningful tests, lint or format the codebase, and build the application reliably. This structure gives you the foundation to iterate and scale your CI/CD pipeline without risking quality or stability.

Key Steps in a Minimal Viable Pipeline
- Trigger builds from pull requests or main branch pushes
Your CI/CD pipeline should automatically run whenever code is pushed to a critical branch or a pull request is opened. This ensures immediate feedback. - Install dependencies and run tests
Include at least unit tests and code format checks. Over time, grow this to include integration tests. Run them in parallel whenever possible to keep the CI/CD pipeline fast. - Build the application
Whether you’re compiling code, generating static assets, or creating Docker images — this step guarantees a working artifact for later deployment. - Lint and enforce formatting
Add a code style step early. Static checks catch errors before test failures and keep team conventions consistent. Every CI/CD pipeline should fail fast on basic issues. - Output build status to your version control platform
Expose the success/failure of the pipeline clearly on each commit or pull request. GitHub Actions, GitLab CI/CD, and CircleCI all support this out of the box.
Real-World Example: GitHub Actions Starter Pipeline
This simple but powerful pipeline structure is used by SolidJS and Astro, and serves as a reliable foundation for open source and product teams alike.
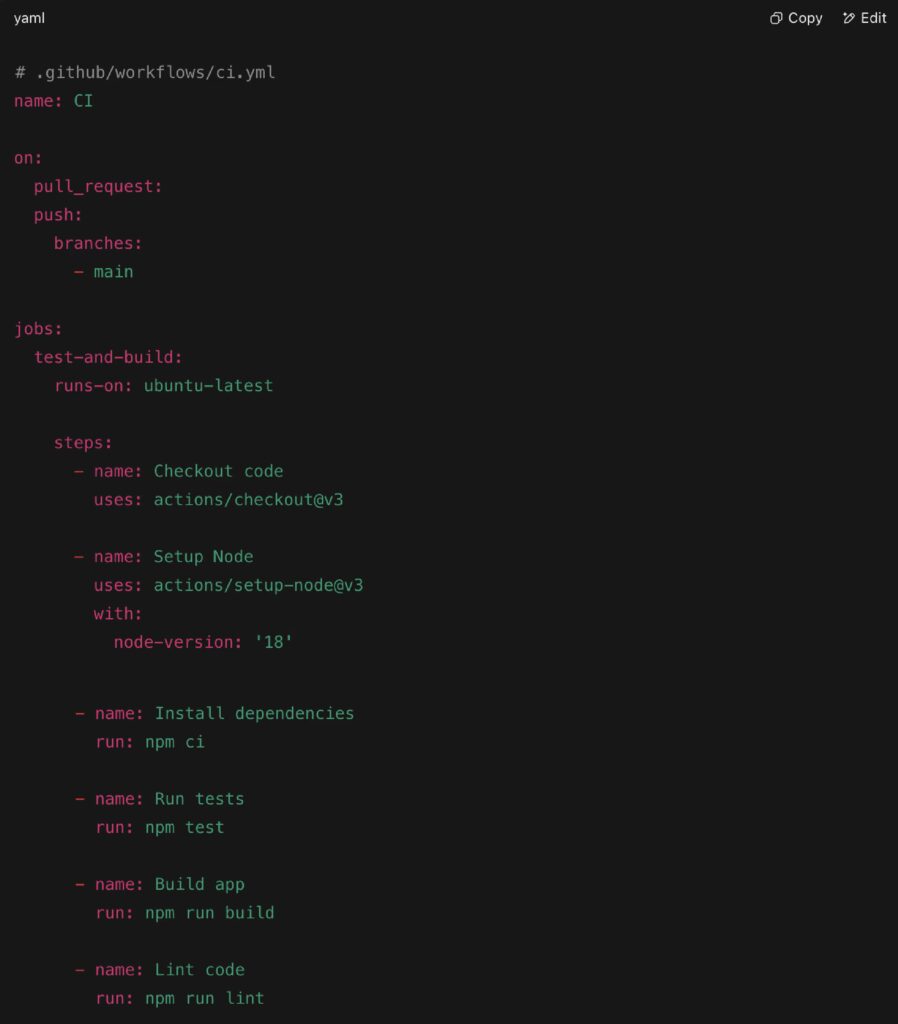
This GitHub Actions setup defines a basic CI/CD pipeline that runs every time code is committed or a pull request is opened. It’s a repeatable, testable foundation that can be expanded over time.
What Comes Next?
Once your minimal pipeline is reliable, you can begin layering on features like:
- Caching dependencies to reduce runtime
- Matrix builds to test multiple runtime environments
- Deploy previews for staging or QA branches
- Secrets management for accessing private APIs or registries
- Persistent artifacts like Docker images or production builds
Each improvement should address an actual bottleneck — not just add complexity. That’s the core value of a strong CI/CD pipeline: it evolves with your team’s needs while staying reliable under pressure.
Automating Tests in the CI/CD Pipeline
A reliable CI/CD pipeline is only as good as its ability to catch problems early. Without automated tests, delivery speed becomes a liability. Modern pipelines aren’t just a sequence of build steps — they’re a safety system. Testing ensures that each change is valid, complete, and doesn’t break critical functionality downstream.
Every CI/CD pipeline should include a thoughtful, layered approach to automated testing. These tests provide fast feedback to developers, ensure application correctness, and reduce the risk of regressions reaching production.
A modern CI/CD pipeline doesn’t just run a single test command — it orchestrates a suite of tests across layers, environments, and dependencies. It ensures code quality and functional integrity from the moment a developer pushes code to the second it’s deployed to production.
Types of Tests to Automate
A well-rounded testing strategy should be layered. Each layer of testing answers a different risk question and serves a different purpose in your CI/CD pipeline:
- Unit tests
- What they check: Individual functions or components in isolation
- Tools: Jest, Mocha, PyTest, JUnit
- When to run: On every push or pull request
- Goal: Fast and parallelizable — ideal for early CI/CD pipeline stages
- Integration tests
- What they check: Multiple components interacting together (e.g., services, DB calls, APIs)
- Tools: Supertest, Postman, Vitest, Spring Test
- When to run: Run mid-pipeline, usually after build or container steps
- Goal: Catch unexpected interactions or misconfigurations
- End-to-end (E2E) tests
- What they check: Full application behavior from the user’s perspective
- Tools: Playwright, Cypress, Selenium
- When to run: On staging branches or nightly builds
- Goal: Simulate real-world workflows and prevent regressions
- Smoke tests
- What they check: Basic app functionality after deployment
- Tools: Shell scripts, HTTP ping tests, cloud health checks
- When to run: After deployment as part of the CI/CD pipeline
- Goal: Verify live systems work before alerting or scaling
Real-World Example: SolidJS Testing Workflow
SolidJS uses a multi-layered testing approach in its GitHub Actions setup. The pipeline tests across multiple Node.js versions, runs compiler validation with integration suites, and executes full E2E workflows using Playwright.
Explore SolidJS on GitHub to see their CI configuration in action here.
By embedding all test stages into its CI/CD pipeline, SolidJS ensures code quality, performance stability, and contributor confidence across every change.
Test Orchestration in Practice
A real-world CI/CD pipeline will need to balance speed and depth. Here’s how to structure testing effectively:
1. Parallelize early-stage tests
Use matrix builds in your CI/CD pipeline to test across environments or versions without adding runtime. Use this to split unit and integration tests into multiple jobs. For example, in GitHub Actions:

This spins up parallel environments to test against all supported Node versions — cutting total pipeline time dramatically.
2. Use test-specific runners or containers
Isolate tests that require databases, browsers, or cloud emulators. Spin up containers with Docker Compose or use services like Cypress Dashboard or Playwright Test Grid to manage dependencies cleanly.
3. Gate merges with test status
All tests should report their outcome back to the PR view in your version control system. This allows teams to enforce status checks and prevents merging broken builds.
4. Use test reports for visibility
Tools like JUnit, Mocha’s reporters, or Allure can generate visual test reports and error traces. Many CI/CD pipeline platforms can surface these reports in dashboards. These make debugging test failures faster and more transparent.
5. Monitor flaky tests
Flaky or unstable tests are worse than no tests. Use retries with a cap, but never ignore persistent failures. Tools like GitHub’s workflow_run + rerun-failed-jobs patterns or CircleCI’s test insights can help identify repeat offenders.
When Testing Enables Delivery
Testing doesn’t slow down development — it enables it. When your CI/CD pipeline is well-tested, engineers ship more confidently, reviewers merge faster, and rollback incidents become rare.
A well-tested CI/CD pipeline also improves security posture, since risky changes are caught before they ever reach production.
Scaling with Confidence
As your app grows, so should your testing. In mature pipelines, teams introduce:
- Test coverage gates (e.g., minimum 80% branch coverage)
- Contract testing for API consistency between services (e.g., Pact, Dredd)
- Security and compliance tests (e.g., OWASP scans, SAST)
In all cases, testing is a moving target. But the earlier and more consistently it’s integrated into your CI/CD pipeline, the more it amplifies developer confidence and product stability.

Deployment Strategies: Making Releases Safer and Smarter
A CI/CD pipeline is only as effective as the confidence it gives you in shipping code. Once tests pass and a build artifact is created, the final step — deployment — is where the most visible and potentially disruptive changes happen. Without a well-defined deployment strategy, even the best-tested code can lead to downtime, data loss, or degraded performance.
In 2025, deployment isn’t about pushing code and hoping for the best. It’s about managing risk, minimizing impact, and building rollback into the delivery process. A mature CI/CD pipeline doesn’t just move code to production — it chooses how that release reaches users.
Key Deployment Strategies for Modern CI/CD Pipelines
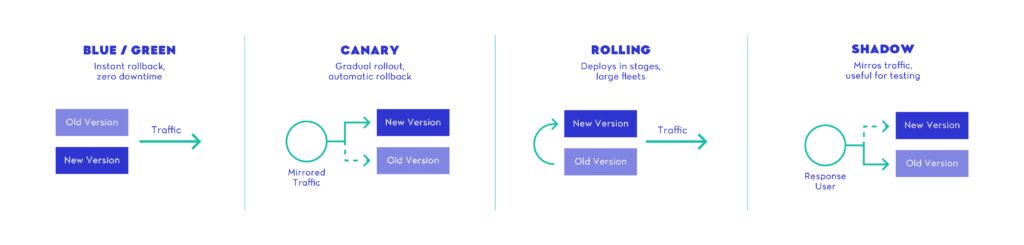
1. Blue/Green Deployment
This approach runs two identical environments: one “blue” (live) and one “green” (idle). New code is deployed to the green environment. Once verified, traffic is switched over instantly.
- When to use it:
Ideal for critical applications where downtime must be zero and rollback must be instant. - Real example:
GOV.UK Platform as a Service (cloud.service.gov.uk) uses blue/green deployment to upgrade services without interruption, relying on AWS ELB to manage the switch between environments.
2. Canary Deployment
With this method, a small portion of traffic (e.g., 5–10%) is routed to the new version first. If no issues are detected, the rollout gradually expands.
- When to use it:
Perfect for consumer apps, APIs, or high-traffic services where monitoring production feedback in real time is critical. - Real example:
Netflix detailed in 2023 how they use canary deployments within their Spinnaker-based CI/CD pipeline to push microservice updates behind feature flags, combined with automatic rollback triggers.
3. Rolling Deployment
This strategy updates nodes or containers one at a time, gradually replacing the old version across the infrastructure.
- When to use it:
Suited for containerized environments and large-scale web apps where constant availability is required. - Real example:
Kubernetes-native deployments use rolling updates by default. Projects like Argo Rollouts extend this pattern with step-based checks and traffic weighting.
4. Shadow Deployment
A non-user-facing deployment where real traffic is mirrored to the new version without affecting actual users.
- When to use it:
Useful for performance testing and service validation in real time, especially with ML models or data pipelines. - Real example:
Shopify uses shadow deployments in their ML-powered fraud detection systems to validate model changes in production conditions before activating them.
Choosing the Right Strategy for Your Pipeline
Here’s how to decide what strategy to build into your CI/CD pipeline:

Most teams evolve toward a hybrid model — starting with rolling updates, then adding canary gating or blue/green paths as their platform matures. These strategies can be automated inside your pipeline using tools like:
- Spinnaker (multi-strategy deployment orchestration)
- Argo Rollouts (Kubernetes-native progressive delivery)
- GitHub Actions + feature flags (e.g., LaunchDarkly)
Automating Rollbacks in CI/CD
Deployment strategies only reduce risk if failures are detectable and reversible. Your CI/CD pipeline should include rollback mechanisms such as:
- Health checks or smoke tests after deploy
- Monitoring thresholds for key metrics (latency, errors, CPU)
- Auto-revert scripts triggered by failure conditions
- Manual rollback buttons in your platform dashboard
For example, Argo CD integrates tightly with Prometheus and Grafana to trigger rollback steps based on service health alerts.
Real-World Example: Argo Rollouts at Intuit
Intuit uses Argo Rollouts, an extension of Argo CD, to implement progressive deployment strategies like canaries and blue-green rollouts at scale. Their platform deploys thousands of services weekly across AWS regions with dynamic traffic shaping, automatic rollback, and integrated monitoring.
This setup ties directly into their CI/CD pipeline, ensuring deployments only proceed when metrics meet success criteria.
Real-World Deployment Flow
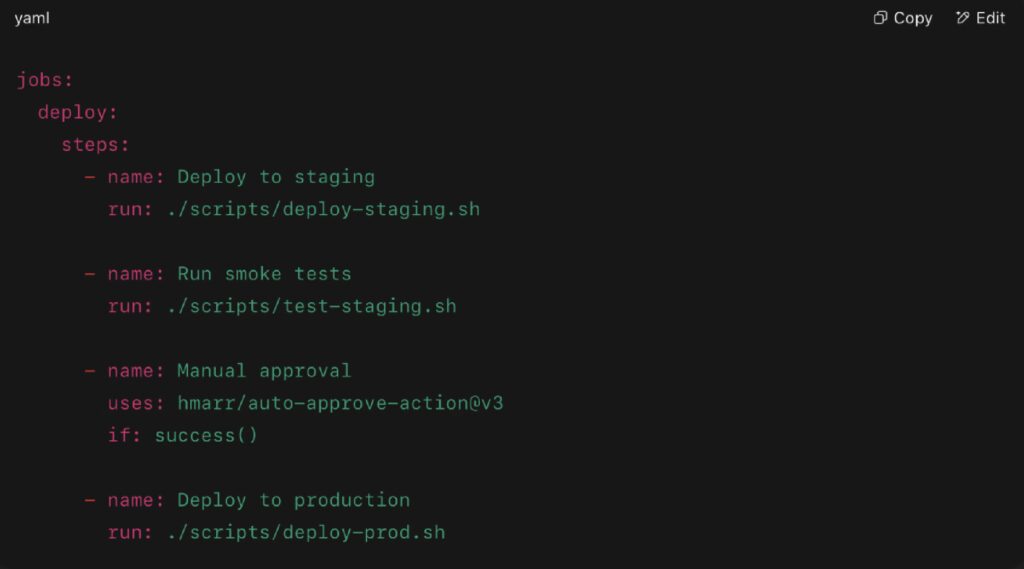
This workflow includes pre-production tests, a manual approval gate, and promotes only healthy builds — one of the best ways to keep deployment safe, even in small teams.
Integrating Deployment into Your CI/CD Pipeline
A strong CI/CD pipeline doesn’t just build artifacts — it controls how those artifacts reach production. To implement these strategies safely:
- Automate rollback on failure (tied to observability signals)
- Define deployment steps as separate jobs or workflows
- Use tools like kubectl, Argo CD, or Helm to manage rollouts
- Trigger deployments conditionally (e.g., on tagged commits or approvals)
- Track success via health probes or custom metrics
Real Toolchains that Support Strategy-Based Deployments
- Argo CD + Argo Rollouts: GitOps-based progressive deployment with built-in analysis and rollback. Click here to explore Argo CD and know more about Argo Rollouts in this link.
- Spinnaker: Used at Netflix for multi-cloud deployments with built-in stage gates. Explore Spinnaker and how it works here.
- Flux CD: Lightweight GitOps deployment tool with Helm and Kustomize support. See how Flux CD works and how you can implement it here.
These platforms act as the deployment engines in your CI/CD pipeline, providing visibility, control, and traceability across environments.
Key Takeaways
Deployment is not a one-size-fits-all decision. A mature CI/CD pipeline adapts its deployment strategy to the service being shipped, the risk tolerance, and the user base. The right delivery method enables faster iteration, safer experimentation, and more resilient infrastructure.
Progressive delivery isn’t just for FAANG teams — it’s becoming the standard for any team operating in production.
Secrets and Pipeline Security
Every well-built CI/CD pipeline needs to handle sensitive data — API keys, tokens, SSH credentials, database passwords, cloud provider secrets. When these secrets are improperly managed, the consequences range from broken deploys to major security breaches. In 2025, with increasing supply chain attacks and credential leaks, securing your CI/CD pipeline is no longer optional — it’s foundational.
Automation doesn’t just move code. It also interacts with production systems, third-party APIs, cloud environments, and infrastructure provisioning tools. That means your CI/CD pipeline must be treated as a privileged system — with strong access control, auditability, and secret isolation.
Common Security Risks in CI/CD Pipelines
- Hardcoded secrets in code or configs
Accidentally committing .env files or AWS keys to version control remains one of the most common attack vectors — even with .gitignore best practices in place. - Plaintext secrets in CI logs or environments
Misconfigured pipelines may echo secrets to logs or leave them exposed in environment variables that are visible to all contributors. - Over-privileged service accounts
Many pipelines run with permissions far broader than necessary, including full write access to production databases or admin-level cloud permissions. - Lack of audit logging or approval flows
Without visibility into who triggered a pipeline or approved a deployment, it’s impossible to detect suspicious behavior or insider threats.
Modern Best Practices for Pipeline Security
To protect sensitive data, modern teams integrate secrets management directly into the CI/CD pipeline, using dedicated tools, scoped access, and encrypted workflows. Here’s how:
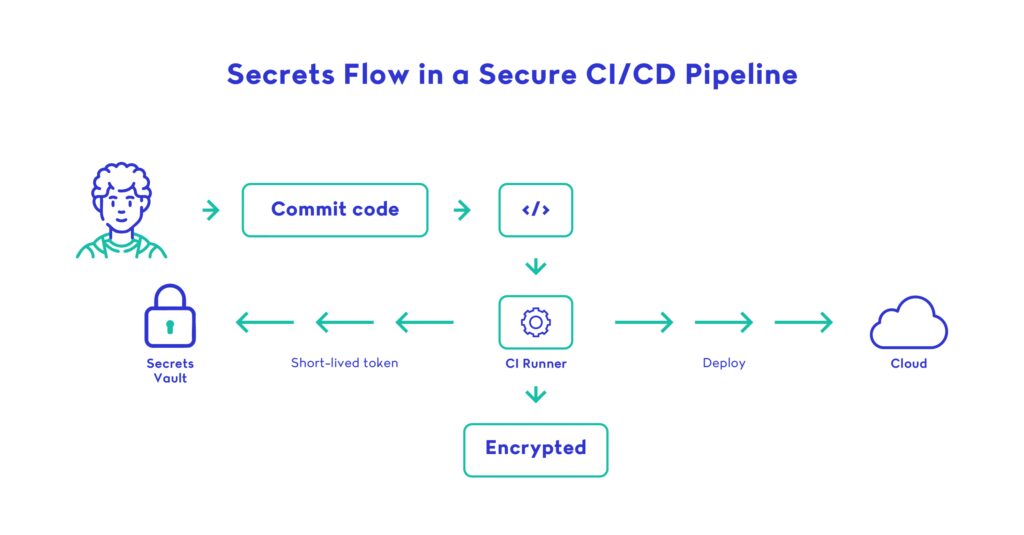
1. Use a Centralized Secrets Manager
Tools like HashiCorp Vault, AWS Secrets Manager, and Azure Key Vault let you store and access secrets securely without ever hardcoding them into the pipeline or app.
- Secrets are encrypted at rest and in transit
- Access can be scoped per environment, branch, or job
- Audit logs track every read or write operation
2. Use OIDC for Temporary Access Tokens
Many platforms now support OIDC (OpenID Connect) authentication flows that generate short-lived access tokens instead of relying on long-term static secrets.
- GitHub Actions supports federated identity with AWS or Azure
- This removes the need to store AWS keys in GitHub at all
- Expired tokens reduce blast radius in case of leaks
3. Set Per-Job Permissions
A modern CI/CD pipeline should not treat all jobs equally. Testing jobs don’t need deployment secrets. Linting jobs don’t need access to production. Use context-aware access control and environment scoping to restrict secrets to only the steps that require them.
4. Encrypt Secrets in Transit
Use platform-level tools to ensure secrets are never passed in plain text. In GitLab CI/CD, variables can be masked and protected. In CircleCI, secrets can be encrypted locally before being used in workflows.
5. Monitor for Secret Leaks
Integrate tools like TruffleHog, Gitleaks, or GitGuardian into your pipeline. These scan code for high-entropy strings or known credential patterns to catch accidental exposure before code merges.
Real-World Example: GitHub OIDC with AWS
In 2023, GitHub Actions introduced OIDC authentication with cloud providers. This allows a CI/CD pipeline to generate a temporary IAM role in AWS using signed identity tokens, removing the need to store AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY at all.
Here’s what a GitHub workflow might include:
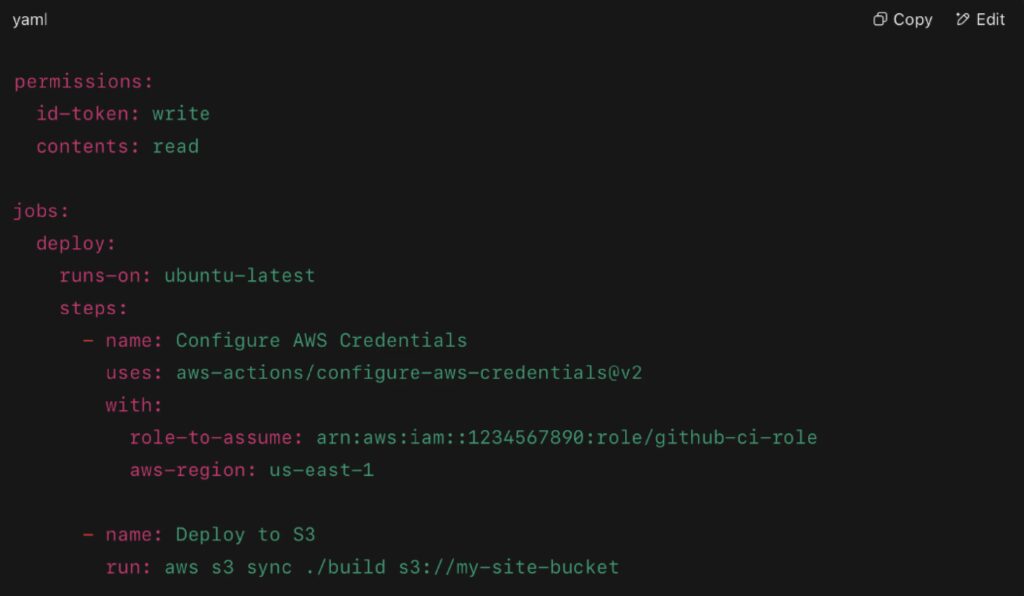
This setup minimizes long-term credential storage, adheres to least privilege, and supports secure multi-environment deployments.
Additional Protections to Consider
- Signed commits and builds: Use Sigstore or GPG to verify source authenticity
- Audit trails: Retain detailed logs of who ran what and when
- Multi-factor approval for production deploys
- Secrets rotation: Automate renewal and invalidation of credentials every 30–90 days
- Static and dynamic application security testing (SAST/DAST) integrated into pipeline stages
Securing the CI/CD Pipeline
The foundation of pipeline security is secret management. In a strong CI/CD pipeline setup, teams follow the principle of least privilege and store credentials in purpose-built tools.
To protect secrets at scale, many engineering teams rely on dedicated secrets managers like HashiCorp Vault. These systems allow for dynamic, scoped secrets per environment or service, with automatic expiration and full audit logs. Instead of embedding sensitive values in .env files or CI variables, secrets are pulled securely by the CI/CD pipeline only when needed — and only for the relevant steps.
In 2023, GitHub Actions launched full support for OIDC-based authentication to AWS, Azure, and Google Cloud, allowing pipelines to authenticate without long-lived credentials. This lets pipelines assume cloud roles at runtime using signed identity tokens. When implemented properly, this eliminates the need to store AWS_ACCESS_KEY_ID or cloud secrets inside CI/CD platforms altogether.
For secret leak detection, companies are increasingly integrating scanning tools like GitGuardian into their development lifecycle. Their 2024 Public Report found that more than 10 million secrets were exposed in public repositories in a single year — most of them by accident. Tools like GitGuardian, TruffleHog, and Gitleaks can scan commits and CI logs for API tokens or high-entropy strings, preventing leaks before they reach production.
Building a Secure Pipeline Culture
To protect secrets at scale, many engineering teams rely on dedicated secrets managers like HashiCorp Vault. These systems allow for dynamic, scoped secrets per environment or service, with automatic expiration and full audit logs. Instead of embedding sensitive values in .env files or CI variables, secrets are pulled securely by the CI/CD pipeline only when needed — and only for the relevant steps.
In 2023, GitHub Actions launched full support for OIDC-based authentication to AWS, Azure, and Google Cloud, allowing pipelines to authenticate without long-lived credentials. This lets pipelines assume cloud roles at runtime using signed identity tokens. When implemented properly, this eliminates the need to store AWS_ACCESS_KEY_ID or cloud secrets inside CI/CD platforms altogether.
For secret leak detection, companies are increasingly integrating scanning tools like GitGuardian into their development lifecycle. Their 2024 Public Report found that more than 10 million secrets were exposed in public repositories in a single year — most of them by accident. Tools like GitGuardian, TruffleHog, and Gitleaks can scan commits and CI logs for API tokens or high-entropy strings, preventing leaks before they reach production.
Observability and Rollback Tactics
Even the most advanced CI/CD pipeline is incomplete without a feedback loop. Observability and rollback mechanisms ensure that teams can monitor what’s happening in production and take corrective action when things go wrong — ideally, before users even notice.
A good CI/CD pipeline not only delivers code to production, but continuously validates that the code is working as intended. This validation spans metrics, logs, traces, and user behavior signals — all of which help determine whether a release should proceed, pause, or be rolled back.
Core Observability Signals to Monitor
Observability is about answering three key questions:
- Is the system working as intended?
- If not, why?
- How quickly can we respond?
To answer these within your CI/CD pipeline, you need to integrate:
- Metrics (latency, throughput, error rates)
- Logs (structured, queryable, and scoped to each deploy)
- Traces (across services and infrastructure layers)
Core Observability Tools (Real-World Use)
1. Prometheus + Grafana
Open-source stack used by thousands of companies to monitor Kubernetes, applications, and infrastructure. Dashboards can be tied to specific pipeline stages or deploy events.
- Example: SoundCloud’s platform team uses Prometheus to monitor deployment health across microservices and ties rollback triggers directly to alert thresholds.
2. Datadog CI Visibility
Commercial tool that visualizes your pipeline’s performance (build times, failures, test flakiness) and also tracks post-deployment metrics.
- Example: HashiCorp documented how they used Datadog to monitor resource usage during Terraform apply steps and flag deploy-time bottlenecks.
3. OpenTelemetry + Honeycomb
For teams using distributed tracing, OpenTelemetry is the modern open standard, and Honeycomb provides powerful event correlation tied to deploy timestamps.
- Example: Grafana Labs in 2023 adopted OpenTelemetry to build “CI/CD observability,” using its traces to surface flakiness and performance regressions earlier in the pipeline, helping engineers catch and fix issues before they reached production.
Connecting Observability to Rollback
The key to safe deploys is not just noticing failures — it’s responding. Your CI/CD pipeline should support one or more rollback mechanisms:
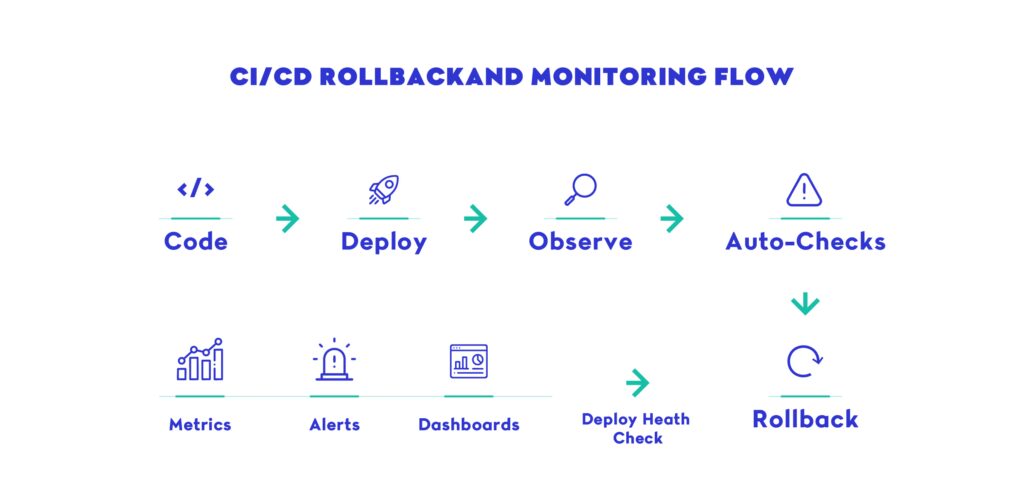
Manual Rollback
Trigger a reversion from the dashboard or CLI (e.g., GitHub Actions “Re-run with previous SHA”).
Automated Rollback
Pipeline checks post-deploy metrics, then runs a rollback script if thresholds are exceeded (e.g., HTTP 500s spike, latency jumps 2x).
GitOps Reconciliation
Tools like Argo CD continuously compare desired state (in Git) with live cluster state. If drift is detected or health checks fail, Argo can auto-revert the change.
- Example: Intuit’s engineering blog describes using Argo CD to detect drift or failed deployments via health checks and automatically revert to a known-good state.
A Sample Observability-Enabled Rollback Workflow
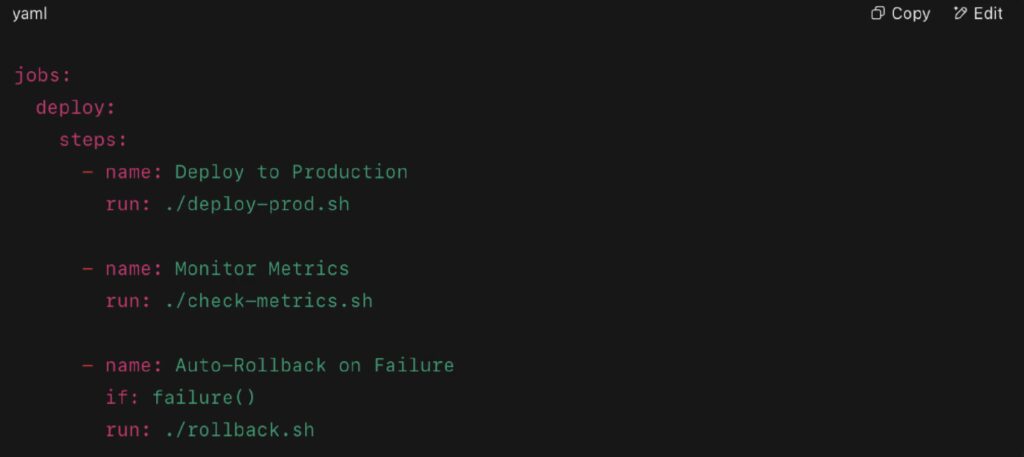
Here, the pipeline deploys, runs post-deploy monitoring scripts, and if a failure threshold is detected, executes a rollback script automatically. All steps are logged, versioned, and observable.
Real-World Example: Netflix Rollback Architecture
Netflix runs an internal rollback service that monitors dozens of signals — CPU, error rates, user sessions — immediately after deployment. If any metric crosses a threshold, the system auto-reverts the change and alerts the release team.
This rollback layer is deeply integrated into their CI/CD pipeline. No human intervention is needed unless the rollback itself fails. Learn more about how top tech companies handle automated rollbacks by consulting the Netflix Tech Blog.
How to Automate Rollbacks in Your CI/CD Pipeline
A resilient CI/CD pipeline should fail forward. That means allowing fast release but also fast recovery. Here’s how to implement automated rollback:
- Define rollback policies tied to real metrics (e.g., 10% 500s within 5 minutes)
- Integrate observability tools that expose deployment health directly to your pipeline
- Store previous build artifacts or Kubernetes manifests for instant reversion
- Keep rollback commands declarative (e.g., Git revert, Helm rollback, Argo sync)
- Test your rollback process in staging — don’t wait until prod to find out it’s broken
Best Practices for Rollback-Ready Pipelines
- Deploy in small, reversible increments
Fewer lines = easier to trace issues and revert. - Include deploy ID or git hash in all logs and traces
Helps correlate metrics and incidents to the exact version deployed. - Store artifacts for each deploy
You can’t roll back if you delete the last known good build. - Expose deploy health in dashboards
CI tools like CircleCI and GitHub Actions can publish deploy status to Grafana using webhooks or Prometheus exporters. - Alert on what matters
Don’t just monitor CPU. Monitor error rates, dropped transactions, or core business metrics (e.g., signups, purchases).
Why It Matters
Without observability, a CI/CD pipeline is blind. Without rollback, it’s brittle. Combined, these two capabilities create a safety net that empowers teams to deploy frequently, fix confidently, and improve continuously.
Investing here transforms CI/CD from a delivery mechanism into a feedback engine — and that’s what modern DevOps is all about.
Your CI/CD pipeline should be capable of stopping a release, reverting a change, or notifying stakeholders without waiting for a post-mortem. This is where observability and rollback strategies shift from “nice to have” to core infrastructure.
Scaling CI/CD with GitOps and Argo CD
As teams grow and applications evolve into dozens — or hundreds — of services, maintaining consistency, visibility, and control becomes a serious challenge. A traditional CI/CD pipeline can start to break down under this scale: YAML sprawl, environment drift, and manual interventions all creep in. This is where GitOps and tools like Argo CD help level up delivery operations.
GitOps is an operational framework that treats Git as the single source of truth for infrastructure and deployments. Combined with Argo CD, it gives platform and DevOps teams a powerful, declarative, and auditable way to deploy and manage complex systems at scale — without overloading the CI/CD pipeline with responsibility it wasn’t designed for.
What is GitOps?
GitOps applies the principles of version control, pull requests, and automation to infrastructure and application delivery. The main idea: instead of pushing changes from your CI/CD pipeline into production, you commit your desired state to Git — and let a controller (like Argo CD or Flux) continuously apply that state to your live environment.
This inversion of control creates a closed feedback loop:
- You declare what you want in Git
- Argo CD reconciles that against what’s actually running
- If drift is detected, it syncs or alerts
This pattern decouples build logic from deployment logic, and improves:
- Auditability (Git logs = deploy history)
- Rollbacks (revert the Git commit = revert the change)
- Security (no need to give pipelines direct access to clusters)
Argo CD in Practice
Argo CD is a Kubernetes-native GitOps controller that continuously syncs Git state with your cluster. It supports multiple environments, applications, and sync strategies — all visualized through a UI or CLI. It doesn’t replace your CI/CD pipeline — it extends it.
Real-world example: Intuit at scale
Intuit uses Argo CD to run GitOps at scale — managing thousands of applications across multiple AWS regions — leveraging automated syncing, Helm-based templating, and strict role-based access controls.
Their setup allows each team to own its own CI/CD pipeline for building code, while deployments are declaratively managed and continuously reconciled by Argo CD. This separation of concerns improves security, rollback, and speed at scale.
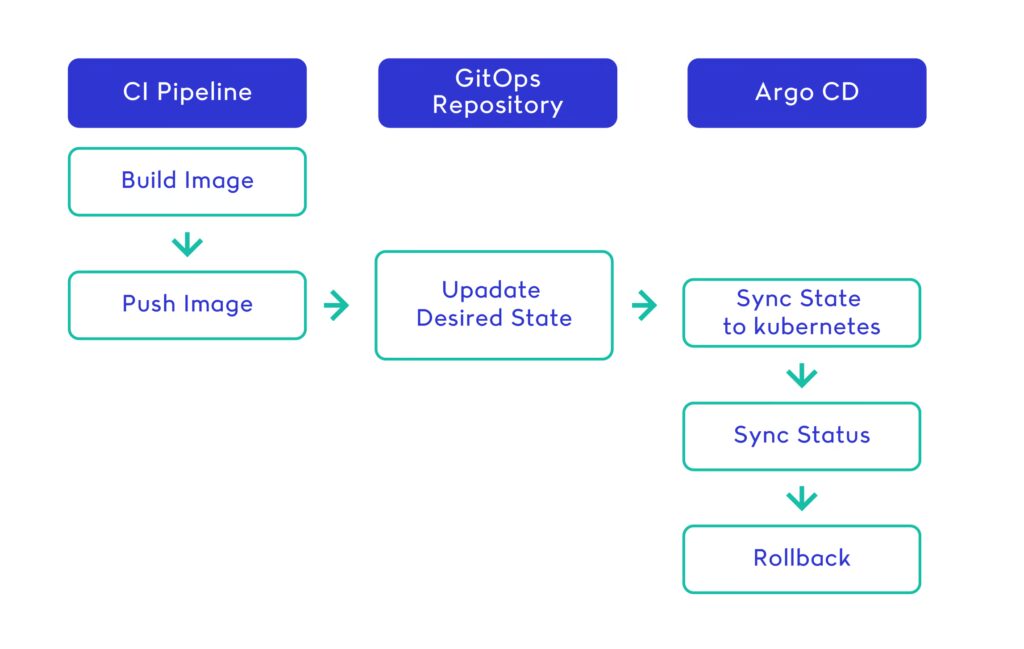
GitOps Workflow Connected to CI/CD
- CI builds the application and pushes a new container
- The updated image tag is committed to Git (via bot or manual PR)
- Argo CD detects the Git change and syncs the cluster
- Health checks verify that the new state is working
- Rollback is as easy as reverting the Git commit
By treating Git as the deployment engine, your CI/CD pipeline becomes a build and test orchestrator — not a single point of failure for production.
Benefits of Scaling with GitOps
- Immutable deploy history — everything is versioned and traceable
- Environment parity — staging and prod are managed identically
- Pull request reviews for infra — no hidden deploy logic
- Clear separation of CI and CD — pipelines build, Argo deploys
- Safe rollbacks — revert a Git commit to undo a broken release
When GitOps Makes Sense
GitOps isn’t just for massive platforms. It’s a solid choice when:
- You manage multiple environments (dev, staging, prod)
- You need strong audit trails and rollback support
- You want to isolate deploy permissions from CI/CD pipeline logic
- You’re building an internal developer platform (IDP) with self-service deployment
Many teams begin by having their CI/CD pipeline update a Git repository instead of directly deploying. Then, Argo CD or Flux handles the sync. This keeps deployment logic visible, peer-reviewed, and repeatable across services.
Mastering CI/CD from End to End
Implementing a reliable, secure, and scalable CI/CD pipeline isn’t just about automating deployments. It’s about building trust in your release process — so your team can move faster without sacrificing quality, stability, or security. From testing and observability to secrets management and GitOps workflows, every layer of the CI/CD pipeline contributes to a broader culture of continuous improvement.
For teams just getting started, building a minimal pipeline with GitHub Actions or GitLab CI/CD can unlock early wins in speed and reliability. For those scaling fast, progressive delivery, Argo CD, and role-based access control will ensure deployments remain predictable under pressure. And regardless of team size, investing in observability and rollback tactics ensures that your CI/CD pipeline becomes a feedback engine — not a blind push mechanism.
At Landskill, we help engineering teams implement production-grade CI/CD pipelines tailored to their platform, team structure, and long-term growth. Whether you’re shipping five times a day or just getting your first release out the door, the right pipeline architecture will help you move faster — with confidence.
In 2025 and beyond, the CI/CD pipeline is more than automation. It’s the operating system of modern software delivery — and mastering it is how teams deliver better software, faster.
