In 2025, organizations are under growing pressure to process information the moment it’s created, which is why real-time data pipelines have become a foundational element in modern engineering strategies. As companies adopt event-driven systems, stream processing platforms, and cloud-native architectures, data pipelines now define how teams deliver insights, automate decisions, and scale analytics workloads. The shift toward streaming-first architectures accelerated in 2024, driven by advancements in systems like Apache Kafka, Apache Flink, and cloud services such as AWS Kinesis, all of which helped mature the ecosystem for real-time data pipelines across industries.
Yet many teams still struggle to understand which approaches work best when building real-time data pipelines for large, distributed environments. The challenge is no longer simply moving data quickly; it’s ensuring consistency, reliability, and observability in data pipelines that span multiple services, regions, and business domains. Companies like Netflix and Uber have published engineering updates describing how they re-architected data pipelines to handle higher throughput and lower latency, revealing both the opportunities and the pitfalls that engineers face today.
This guide breaks down five proven design patterns shaping how engineers plan, build, and maintain real-time data pipelines. Each pattern includes practical context and tradeoffs that teams need to understand before deploying to production. For readers looking to connect these architectural decisions to broader engineering practices, the role of operational reliability is explored in our CI/CD Pipeline Automation Complete Guide for DevOps. By the end, you’ll have a clear, modern framework for selecting and implementing real-time data pipelines that support scale, resilience, and long-term evolution.
Below is a concise checklist summarising the five most important design patterns for real-time data pipelines. Each point reflects practical patterns widely adopted in 2024 and 2025 to help teams design, scale, and monitor real-time data pipelines effectively.
- Use event-driven ingestion to decouple producers and consumers.
- Apply stateful stream processing for accurate joins, aggregations, and enrichment inside real-time data pipelines.
- Consolidate batch and streaming workloads by adopting modernised Lambda or Kappa architectures for data pipelines.
- Implement micro-batching where ultra-low latency is not required to reduce compute costs.
- Strengthen orchestration and observability with tools designed for continuous, high-volume operations in data pipelines.
Pattern 1: Event-Driven Ingestion
Event-driven ingestion is the architectural entry point for most real-time data pipelines because it dictates how events first reach the system and how reliably downstream components can react to them. As organizations adopt streaming-first and service-oriented architectures, this pattern ensures that these maintain low latency, predictable ordering, and strong durability guarantees. Platforms such as Apache Kafka, AWS Kinesis, and Google Pub/Sub became significantly more capable after their 2024 updates, which reinforced why event-driven ingestion is now a central requirement for high-throughput data pipelines across industries.
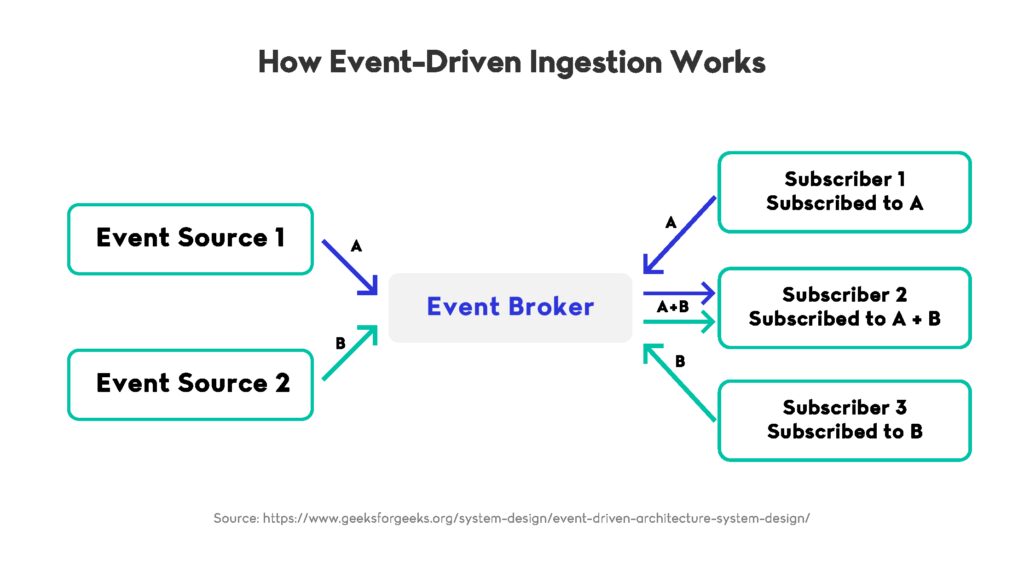
Core Principles of Event-Driven Ingestion
Event-driven ingestion is based on a publish–subscribe model where producers emit events to a durable log and consumers process those events independently. This decoupled flow helps real-time data pipelines scale more easily while remaining stable under heavy load. Kafka’s 2024 improvements, including the stabilisation of KRaft metadata management and expanded tiered storage, reduced operational complexity and improved cluster reliability, allowing real-time data pipelines to operate continuously without controller bottlenecks or storage pressure.
Partitioning, Ordering, and Throughput
Partitioning enables teams to distribute events across multiple shards, which increases throughput and preserves ordering within each partition. These characteristics are important when teams need data pipelines to process high-velocity streams reliably. Proper partition strategy prevents hotspots, and consistent ordering supports critical use cases such as fraud detection, mobility pricing, and behavioural analytics. These capabilities ensure that they behave predictably even when event volumes surge.
Real-World Implementations
Several companies shared engineering updates that illustrate how event-driven ingestion supports large-scale real-time data pipelines. Uber published details on the Uber Engineering Blog describing how Kafka ingestion paths were redesigned to reduce latency during peak ride activity in 2024. Netflix discussed improvements to Keystone, its internal streaming platform, on the Netflix Tech Blog, showing how enhanced ingestion logic improved schema handling and throughput for enterprise-scale real-time data pipelines. These examples highlight how this pattern performs under real-world constraints.
Benefits and Tradeoffs
The primary advantage of event-driven ingestion is its flexibility: producers and consumers evolve independently, and events can be replayed if downstream services need reprocessing. These strengths help real-time data pipelines remain resilient during rapid growth or architectural changes. However, operational challenges also exist. Teams must manage schema evolution carefully, maintain balanced partitions, and monitor consumer groups to prevent lag. These factors determine how consistently real-time data pipelines deliver insights and power applications that depend on precise, low-latency data.
Event-driven ingestion therefore forms the structural foundation for all other architectural approaches. It sets the expectations for reliability, scalability, and consistency that real-time data pipelines must meet as they expand and adapt to new business requirements.
Pattern 2: Stream Processing with Stateful Operators
Stream processing with stateful operators has become essential because many applications depend on understanding how events relate to one another over time. Rather than treating each record as an isolated action, this approach enables systems to perform aggregations, joins, time-window operations, enrichment, and behavioural detection with continuity and precision. As streaming workloads grew more complex from 2024 onward, stateful processing emerged as a way to provide the depth and context required for both operational and analytical decision-making.
Why State Matters in Continuous Processing
Stateful operators maintain context across event streams, enabling real-time data pipelines to track evolving patterns rather than respond only to single-point events. Systems such as Apache Flink and Kafka Streams continued to mature in 2024, with Flink’s unified batch-and-stream runtime stabilising and becoming widely adopted for low-latency workloads. Features like checkpointing, savepoints, and RocksDB-backed state stores allow real-time data pipelines to recover correctly after failures and resume complex computations without losing progress.
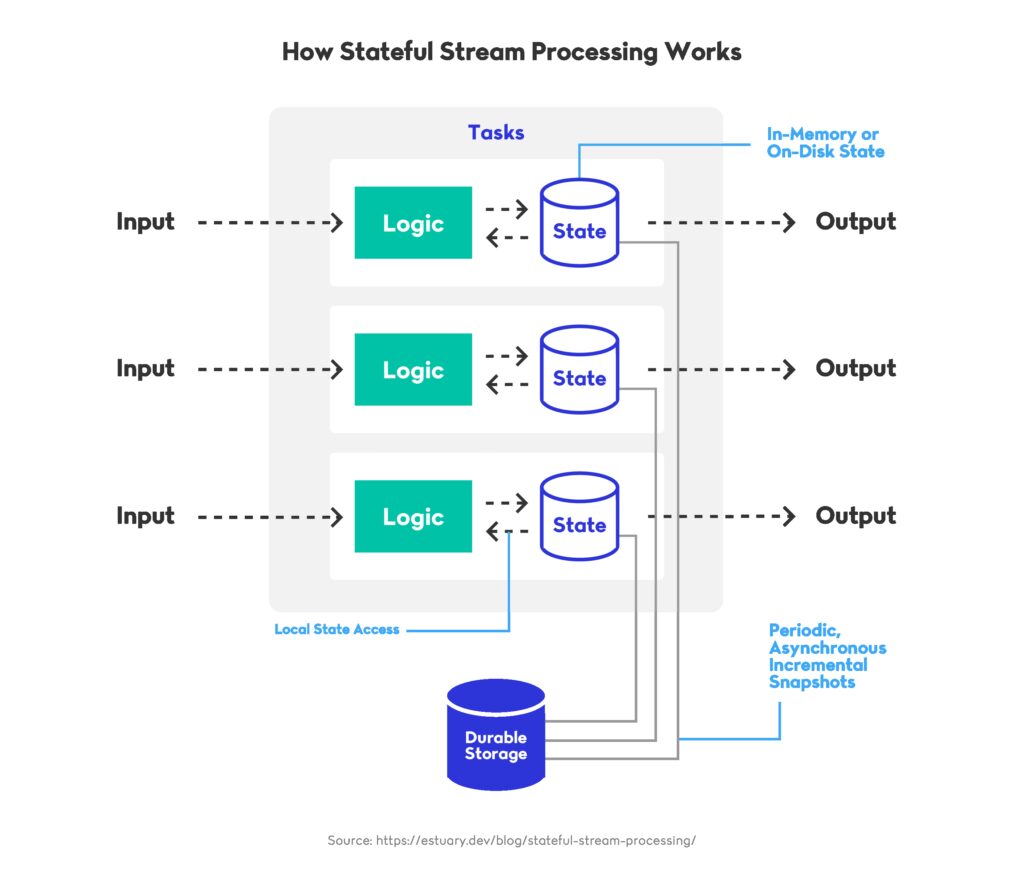
Industry Examples
Several companies publicly documented how stateful processing strengthens real-time data pipelines at large scale. Alibaba shared updates on the Alibaba Cloud Blog describing how Apache Flink powers their recommendation systems by maintaining high-volume keyed state in memory. Confluent highlighted performance improvements to Kafka Streams in 2024, including more efficient RocksDB state store management, as covered on this Confluent Blog article. These examples demonstrate how stateful operators help real-time data pipelines deliver reliable insights even under intense, continuous workloads.
Operational Considerations and Tradeoffs
State introduces important operational requirements. Backpressure must be managed carefully to prevent overloaded tasks, checkpoint intervals must be tuned to avoid long recovery times, and state stores must be sized and monitored to prevent latency spikes. Real-time data pipelines also need strategies for handling hot keys that skew load across partitions. When managed effectively, stateful processing supports critical use cases such as fraud scoring, inventory consistency, operational monitoring, and personalised digital experiences.
How Stateful Operators Strengthen the Overall Architecture
Stateful stream processing expands what real-time data pipelines can accomplish by enabling analysis of patterns, sequences, and relationships rather than simple event-by-event reactions. It allows operational systems to incorporate analytical logic directly into real-time flows, reducing the need for parallel infrastructures. As organizations move away from batch-heavy architectures, this pattern ensures that real-time data pipelines can meet both immediate operational requirements and broader analytical goals within a single continuous framework.
Pattern 3: Lambda and Kappa Architectures
Lambda and Kappa architectures continue to influence how teams design real-time data pipelines, but their modern forms differ significantly from the models first introduced a decade ago. As organizations moved toward unified processing engines and streaming-first platforms, both architectures evolved to support the changing demands of real-time data pipelines. The shift has been driven by the need to reduce system duplication, streamline operational complexity, and ensure that real-time data pipelines deliver consistent results without maintaining separate paths for batch and streaming data.
How Lambda Architecture Has Evolved
The traditional Lambda approach uses two parallel layers: a batch pipeline for accuracy and a streaming pipeline for speed. This dual structure once addressed the limitations of early stream processors but is now considered operationally heavy. Real-time data pipelines today often avoid fully separate layers because maintaining two distinct code paths increases cost and slows iteration. Engineering teams have acknowledged this shift publicly. For example, LinkedIn’s move toward a unified Samza-based streaming model was described on the LinkedIn Engineering Blog, highlighting how a single processing layer simplified their real-time data pipelines and reduced long-term maintenance.
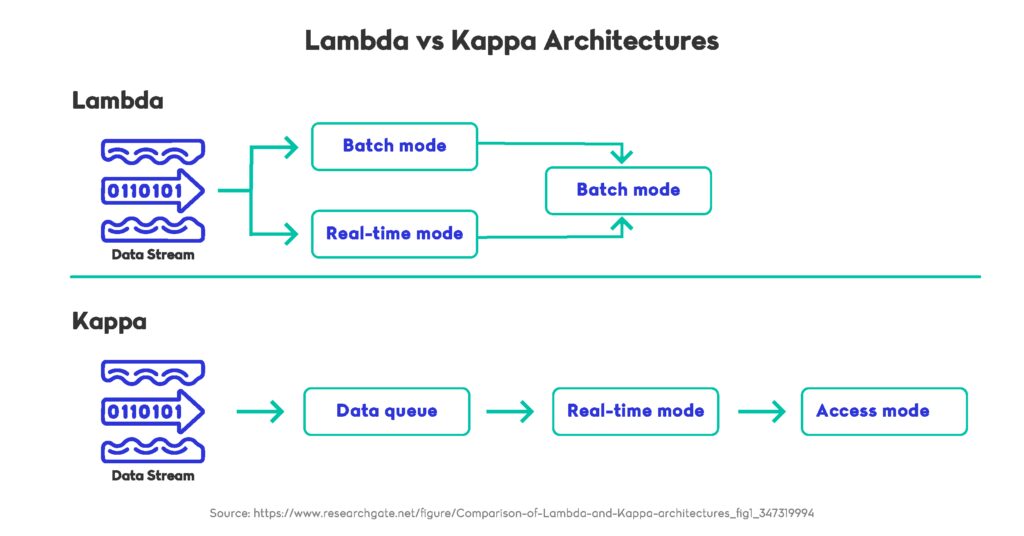
The Modern Rise of Kappa Architecture
The Kappa model takes a different approach by relying solely on a streaming layer that can reprocess data when necessary. This design aligns more closely with today’s real-time data pipelines because modern stream processors can handle both historical and live workloads. The architecture became more practical after the introduction of log-compacted topics, incremental checkpoints, and low-latency state stores in tools such as Apache Flink and Kafka Streams. Databricks also contributed to this trend, describing how Delta Live Tables reduced the need for dual systems in 2024 on the Databricks Blog, showing how unified processing improved reliability for large-scale real-time data pipelines.
Practical Considerations for Unified Architectures
Selecting between Lambda, Kappa, or a modern hybrid depends on workload requirements, latency expectations, and reprocessing needs. Unified pipelines reduce complexity but place greater emphasis on strong ingestion logs, durable state management, and properly governed schemas. These factors influence how real-time data pipelines recover from failures, maintain ordering guarantees, and adapt to new requirements. Many teams now adopt a Kappa-heavy design with selective batch components, allowing real-time data pipelines to remain flexible without duplicating infrastructure unnecessarily.
Why Modernisation Matters
The updated forms of Lambda and Kappa architectures offer engineering teams a more efficient blueprint for scaling real-time data pipelines. Unified streaming layers reduce operational friction, simplify monitoring, and help maintain consistent logic across workloads. As businesses continue to rely on rapid insights, these modernised architectures ensure that real-time data pipelines remain both resilient and adaptable, supporting long-term evolution without the constraints of legacy patterns.
Pattern 4: Micro-Batching for Cost Efficiency
Micro-batching remains a practical design pattern for teams that need the responsiveness of real-time data pipelines without incurring the ongoing cost of fully event-by-event processing. Instead of handling each event individually, micro-batching groups small sets of records into compact processing intervals. This approach offers a balance between the immediacy expected from real-time data pipelines and the affordability needed for workloads with fluctuating traffic. As cloud compute pricing shifted throughout 2024 and 2025, micro-batching became a preferred strategy for organizations optimising both performance and budget within real-time data pipelines.
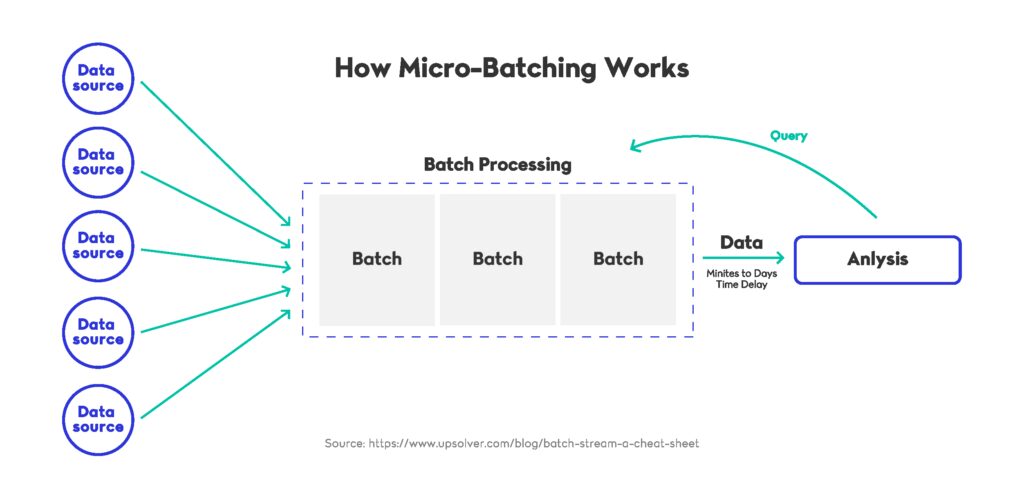
When Micro-Batching Still Makes Sense
Although streaming engines have advanced significantly, there are many practical cases where strict per-event execution adds unnecessary overhead. Micro-batching enables real-time data pipelines to process data at sub-second or near-real-time intervals, which is often sufficient for dashboards, compliance reporting, log aggregation, behavioural analytics, and operational metrics. Databricks continued improving Structured Streaming throughout 2024, demonstrating how adaptive micro-batch scheduling can reduce total cluster costs while supporting continuous workloads, as noted on the Databricks Blog. This reinforced the viability of micro-batching as a middle ground for real-time data pipelines that do not require millisecond-level accuracy.
How Cloud Platforms Support Micro-Batch Designs
Several cloud services now embrace micro-batching as a built-in processing model. Snowflake introduced Dynamic Tables in 2024, allowing near-real-time transformations without requiring a fully streaming engine. This provided a simpler operational model for teams building real-time data pipelines that need rapid updates without the complexity of managing dedicated stream processors, as explained on the Snowflake Blog. By combining periodic refresh cycles with incremental computation, these systems reduced the computational footprint of real-time data pipelines while maintaining freshness for most analytical use cases.
Cost Tradeoffs and Limitations
Micro-batching does come with latency tradeoffs. While it lowers cost, it introduces small delays between event arrival and processing, which may not be acceptable for fraud detection, dynamic pricing, or alerting systems. Teams must also tune batch intervals carefully to avoid spikes in throughput that could overload downstream systems. When applied effectively, micro-batching reduces infrastructure consumption by smoothing event flow, allowing real-time data pipelines to deliver consistent performance even under varied traffic patterns. This makes it an appealing option for organizations balancing precision, speed, and cost.
Why Micro-Batching Remains Relevant
Micro-batching continues to play an important role because it addresses a gap between pure streaming and traditional batch systems. It helps real-time data pipelines operate with predictable cloud costs while preserving the agility needed for modern analytics and operational intelligence. As more engines adopt hybrid execution models, micro-batching ensures that real-time data pipelines remain flexible enough to support diverse workloads without requiring teams to commit fully to streaming-only architectures.
Pattern 5: Real-Time Orchestration and Observability
Orchestration and observability have become essential components of modern real-time data pipelines, as organizations increasingly rely on systems that operate continuously and require precise coordination of tasks. As these pipelines grow in complexity, orchestration ensures that real-time data pipelines run in the correct order, respond to failures, and adapt to workload changes. Observability complements this by providing visibility into performance, latency, lineage, and system health. Together, these two capabilities help real-time data pipelines maintain reliability under unpredictable traffic patterns and evolving business requirements.
Why Orchestration Matters in Streaming Environments
Traditional schedulers were designed for batch workloads, which execute at fixed intervals and tolerate higher latency. Real-time environments demand continuous execution, event-driven triggers, and dynamic scaling. This shift drove the adoption of modern orchestration platforms such as Dagster, Prefect 3.0, and Astronomer, each of which added features in 2024 to support long-running streaming jobs. These platforms help real-time data pipelines coordinate ingestion, transformation, enrichment, and delivery steps while maintaining strict ordering and resilience.
Observability as a Foundation for Operational Reliability
Observability provides the feedback loops required to run real-time data pipelines reliably at scale. Metrics, logs, and traces must be captured continuously so teams can detect anomalies, diagnose bottlenecks, and understand pipeline behaviour. In 2024, companies such as Shopify published insights on how they improved observability for high-throughput streaming systems, highlighting the role of distributed tracing and structured logging. Without these capabilities, real-time data pipelines can degrade silently or deliver inconsistent results.
Industry Applications and Best Practices
Engineering teams increasingly rely on declarative orchestration and enhanced observability to manage real-time data pipelines across multiple environments. Features such as automated retries, event-driven workflows, schema validation, and lineage tracking ensure that real-time data pipelines remain consistent and auditable. Organizations also prioritise service-level objectives that measure end-to-end latency, throughput, and error budgets, giving teams a clearer sense of pipeline performance. These practices help real-time data pipelines operate predictably even when underlying infrastructure or data volumes change rapidly.
Strengthening the Overall Architecture
Real-time orchestration and observability elevate the stability of real-time data pipelines by introducing governance, automation, and continuous feedback. They ensure that every component of the pipeline works together as a cohesive system rather than a set of isolated tasks. As demand for immediate insights increases, these capabilities help real-time data pipelines remain reliable, maintainable, and aligned with business objectives, even as the underlying technologies continue to evolve.
Strengthening the Future of Real-Time Data Pipelines
As organizations continue expanding their digital platforms, the role of real-time data pipelines becomes central to how teams understand user behaviour, automate operations, and respond to fast-changing conditions. The design patterns explored in this guide show how real-time data pipelines can evolve to support increasingly complex workloads without sacrificing reliability or scalability. With event-driven systems becoming more widespread, as discussed in this Event-Driven Architecture at Scale article, engineering teams now have a clearer path for aligning architectural choices with long-term business needs. This shift reinforces the idea that real-time data pipelines must be both adaptable and resilient as new demands emerge.
Modern tools and platforms are reducing the operational burden of running continuous systems, making it easier to build real-time data pipelines that deliver consistent performance under variable load. At the same time, improvements in orchestration, observability, and unified processing models help ensure that real-time data pipelines remain manageable as teams scale their environments. By applying the patterns covered in this guide, organizations can strengthen the durability and flexibility of their real-time data pipelines and prepare for future advancements in streaming technologies.


